Wiki Faces is a project that aims to visualize the life spans and portraits of human figures who constitute the sums of our current scientific knowledge. Wikipedia is the most popular knowledge reference which functions on a technology that completely transformed the way humans retrieve knowledge – the Internet. With this in mind, Wikipedia continues to be one of the most predominant organizations that represents the openness of the Internet. It is believed among some people that in case of a distress that humanity may encounter, Wikipedia would be on of the first sums of human knowledge that would be salvaged.
- Link to Visualization (works best in Chrome browser)
- Wiki Faces on GitHub
- Google Slide
Events like the destruction of Library of Alexandria during the Muslim conquest of Egypt in AD 642, demonstrated how one of the most valuable resources of human knowledge perished following an unfortunate event. Wikipedia has a page dedicated to Terminal Event Management Policy which outlines the steps that must be undertaken in order to safeguard the content of the encyclopedia.
 The destruction of Library of Alexandria. It was one of the largest and most significant libraries of the ancient world, almost like Wikipedia is today.
The destruction of Library of Alexandria. It was one of the largest and most significant libraries of the ancient world, almost like Wikipedia is today.
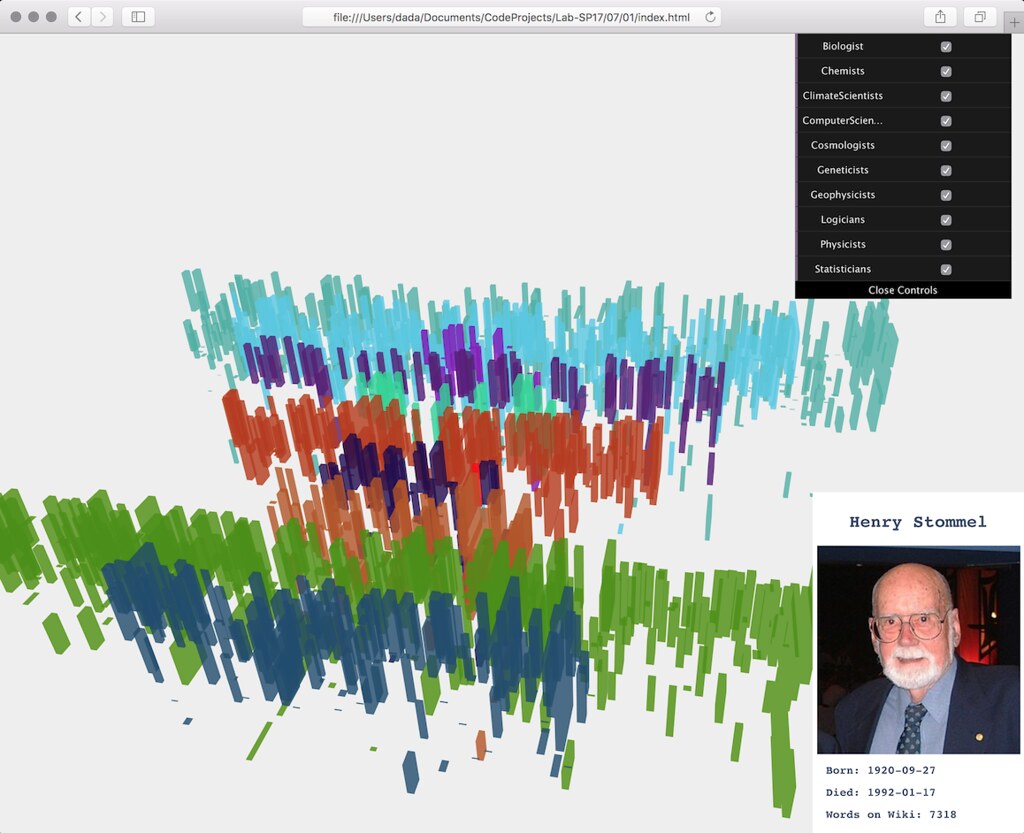
With this in mind, Wiki Faces aims to visualize and represent the faces of people who contributed to the establishment of this sum of human collective knowledge. Without biologist, chemists, historians and thousands of other types of human figures, there would not be sufficient human curiosity for something like an encyclopedia or a Wikipedia to even come into existence.
The visualization is divided into categories of scientists where each is represented by a timeline based on their date of birth and death, and the height of their box reflects the amount of text that is written about them on Wikipedia.
Postscript I
(April 30, 2017)
It has come to my attention and awareness that Wikipedia is by far a lesser sum of all of human knowledge than Google. Google is trying to scan more that 120 million books that are currently known, and use it to improve its search results and it already scanned almost 30 million of them.1 Google is basically the modern equivalent of the Library of Alexandria, which in fact, is not a library that is publicly accessible. Google’s book scanning project is not the same as Google Books which is a platform that sales electronic and physical books. With the scanning project instead, Google is taking advantage of the fair the use policy to improve it search results and potentially other research projects. Fair use is described as follows on Wikipedia:
Fair use is one of the limitations to copyright intended to balance the interests of copyright holders with the public interest in the wider distribution and use of creative works by allowing certain limited uses that might otherwise be considered infringement.2
Google is exercising its rights against book copyright holders to create the biggest sum of human knowledge and nobody has full access to it, apart from a dozen of computer scientists and engineers who maintain the project. Whether this is a malevolent or a benevolent circumstance remains to be seen as it unfolds.
-
James Somers. Torching the Modern-Day Library of Alexandria The Atlantic, Published Apr 20, 2017. ↩